


Image Segmentation DeepLabV3 on iOS¶
Author: Jeff Tang
Reviewed by: Jeremiah Chung
Introduction¶
Semantic image segmentation is a computer vision task that uses semantic labels to mark specific regions of an input image. The PyTorch semantic image segmentation DeepLabV3 model can be used to label image regions with 20 semantic classes including, for example, bicycle, bus, car, dog, and person. Image segmentation models can be very useful in applications such as autonomous driving and scene understanding.
In this tutorial, we will provide a step-by-step guide on how to prepare and run the PyTorch DeepLabV3 model on iOS, taking you from the beginning of having a model you may want to use on iOS to the end of having a complete iOS app using the model. We will also cover practical and general tips on how to check if your next favorite pre-trained PyTorch models can run on iOS, and how to avoid pitfalls.
Note
Before going through this tutorial, you should check out PyTorch Mobile for iOS and give the PyTorch iOS HelloWorld example app a quick try. This tutorial will go beyond the image classification model, usually the first kind of model deployed on mobile. The complete code repo for this tutorial is available here.
Learning Objectives¶
In this tutorial, you will learn how to:
Convert the DeepLabV3 model for iOS deployment.
Get the output of the model for the example input image in Python and compare it to the output from the iOS app.
Build a new iOS app or reuse an iOS example app to load the converted model.
Prepare the input into the format that the model expects and process the model output.
Complete the UI, refactor, build and run the app to see image segmentation in action.
Pre-requisites¶
PyTorch 1.6 or 1.7
torchvision 0.7 or 0.8
Xcode 11 or 12
Steps¶
1. Convert the DeepLabV3 model for iOS deployment¶
The first step to deploying a model on iOS is to convert the model into the TorchScript format.
Note
Not all PyTorch models can be converted to TorchScript at this time because a model definition may use language features that are not in TorchScript, which is a subset of Python. See the Script and Optimize Recipe for more details.
Simply run the script below to generate the scripted model deeplabv3_scripted.pt:
import torch
# use deeplabv3_resnet50 instead of deeplabv3_resnet101 to reduce the model size
model = torch.hub.load('pytorch/vision:v0.8.0', 'deeplabv3_resnet50', pretrained=True)
model.eval()
scriptedm = torch.jit.script(model)
torch.jit.save(scriptedm, "deeplabv3_scripted.pt")
The size of the generated deeplabv3_scripted.pt model file should be around 168MB. Ideally, a model should also be quantized for significant size reduction and faster inference before being deployed on an iOS app. To have a general understanding of quantization, see the Quantization Recipe and the resource links there. We will cover in detail how to correctly apply a quantization workflow called Post Training Static Quantization to the DeepLabV3 model in a future tutorial or recipe.
2. Get example input and output of the model in Python¶
Now that we have a scripted PyTorch model, let’s test with some example inputs to make sure the model works correctly on iOS. First, let’s write a Python script that uses the model to make inferences and examine inputs and outputs. For this example of the DeepLabV3 model, we can reuse the code in Step 1 and in the DeepLabV3 model hub site. Add the following code snippet to the code above:
from PIL import Image
from torchvision import transforms
input_image = Image.open("deeplab.jpg")
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
output = model(input_batch)['out'][0]
print(input_batch.shape)
print(output.shape)
Download deeplab.jpg from here and run the script above to see the shapes of the input and output of the model:
torch.Size([1, 3, 400, 400])
torch.Size([21, 400, 400])
So if you provide the same image input deeplab.jpg of size 400x400 to the model on iOS, the output of the model should have the size [21, 400, 400]. You should also print out at least the beginning parts of the actual data of the input and output, to be used in Step 4 below to compare with the actual input and output of the model when running in the iOS app.
3. Build a new iOS app or reuse an example app and load the model¶
First, follow Step 3 of the Model Preparation for iOS recipe to use our model in an Xcode project with PyTorch Mobile enabled. Because both the DeepLabV3 model used in this tutorial and the MobileNet v2 model used in the PyTorch HelloWorld iOS example are computer vision models, you may choose to start with the HelloWorld example repo as a template to reuse the code that loads the model and processes the input and output.
Now let’s add deeplabv3_scripted.pt and deeplab.jpg used in Step 2 to the Xcode project and modify ViewController.swift to resemble:
class ViewController: UIViewController {
var image = UIImage(named: "deeplab.jpg")!
override func viewDidLoad() {
super.viewDidLoad()
}
private lazy var module: TorchModule = {
if let filePath = Bundle.main.path(forResource: "deeplabv3_scripted",
ofType: "pt"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't load the model file!")
}
}()
}
Then set a breakpoint at the line return module and build and run the app. The app should stop at the breakpoint, meaning that the scripted model in Step 1 has been successfully loaded on iOS.
4. Process the model input and output for model inference¶
After the model loads in the previous step, let’s verify that it works with expected inputs and can generate expected outputs. As the model input for the DeepLabV3 model is an image, the same as that of the MobileNet v2 in the HelloWorld example, we will reuse some of the code in the TorchModule.mm file from HelloWorld for input processing. Replace the predictImage method implementation in TorchModule.mm with the following code:
- (unsigned char*)predictImage:(void*)imageBuffer {
// 1. the example deeplab.jpg size is size 400x400 and there are 21 semantic classes
const int WIDTH = 400;
const int HEIGHT = 400;
const int CLASSNUM = 21;
at::Tensor tensor = torch::from_blob(imageBuffer, {1, 3, WIDTH, HEIGHT}, at::kFloat);
torch::autograd::AutoGradMode guard(false);
at::AutoNonVariableTypeMode non_var_type_mode(true);
// 2. convert the input tensor to an NSMutableArray for debugging
float* floatInput = tensor.data_ptr<float>();
if (!floatInput) {
return nil;
}
NSMutableArray* inputs = [[NSMutableArray alloc] init];
for (int i = 0; i < 3 * WIDTH * HEIGHT; i++) {
[inputs addObject:@(floatInput[i])];
}
// 3. the output of the model is a dictionary of string and tensor, as
// specified at https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101
auto outputDict = _impl.forward({tensor}).toGenericDict();
// 4. convert the output to another NSMutableArray for easy debugging
auto outputTensor = outputDict.at("out").toTensor();
float* floatBuffer = outputTensor.data_ptr<float>();
if (!floatBuffer) {
return nil;
}
NSMutableArray* results = [[NSMutableArray alloc] init];
for (int i = 0; i < CLASSNUM * WIDTH * HEIGHT; i++) {
[results addObject:@(floatBuffer[i])];
}
return nil;
}
Note
The model output is a dictionary for the DeepLabV3 model so we use toGenericDict to correctly extract the result. For other models, the model output may also be a single tensor or a tuple of tensors, among other things.
With the code changes shown above, you can set breakpoints after the two for loops that populate inputs and results and compare them with the model input and output data you saw in Step 2 to see if they match. For the same inputs to the models running on iOS and Python, you should get the same outputs.
All we have done so far is to confirm that the model of our interest can be scripted and run correctly in our iOS app as in Python. The steps we walked through so far for using a model in an iOS app consumes the bulk, if not most, of our app development time, similar to how data preprocessing is the heaviest lift for a typical machine learning project.
5. Complete the UI, refactor, build and run the app¶
Now we are ready to complete the app and the UI to actually see the processed result as a new image. The output processing code should be like this, added to the end of the code snippet in Step 4 in TorchModule.mm - remember to first remove the line return nil; temporarily put there to make the code build and run:
// see the 20 semantic classes link in Introduction
const int DOG = 12;
const int PERSON = 15;
const int SHEEP = 17;
NSMutableData* data = [NSMutableData dataWithLength:
sizeof(unsigned char) * 3 * WIDTH * HEIGHT];
unsigned char* buffer = (unsigned char*)[data mutableBytes];
// go through each element in the output of size [WIDTH, HEIGHT] and
// set different color for different classnum
for (int j = 0; j < WIDTH; j++) {
for (int k = 0; k < HEIGHT; k++) {
// maxi: the index of the 21 CLASSNUM with the max probability
int maxi = 0, maxj = 0, maxk = 0;
float maxnum = -100000.0;
for (int i = 0; i < CLASSNUM; i++) {
if ([results[i * (WIDTH * HEIGHT) + j * WIDTH + k] floatValue] > maxnum) {
maxnum = [results[i * (WIDTH * HEIGHT) + j * WIDTH + k] floatValue];
maxi = i; maxj = j; maxk = k;
}
}
int n = 3 * (maxj * width + maxk);
// color coding for person (red), dog (green), sheep (blue)
// black color for background and other classes
buffer[n] = 0; buffer[n+1] = 0; buffer[n+2] = 0;
if (maxi == PERSON) buffer[n] = 255;
else if (maxi == DOG) buffer[n+1] = 255;
else if (maxi == SHEEP) buffer[n+2] = 255;
}
}
return buffer;
The implementation here is based on the understanding of the DeepLabV3 model which outputs a tensor of size [21, width, height] for an input image of width*height. Each element in the width*height output array is a value between 0 and 20 (for a total of 21 semantic labels described in Introduction) and the value is used to set a specific color. Color coding of the segmentation here is based on the class with the highest probability, and you can extend the color coding for all classes in your own dataset.
After the output processing, you will also need to call a helper function to convert the RGB buffer to an UIImage instance to be shown on UIImageView. You can refer to the example code convertRGBBufferToUIImage defined in UIImageHelper.mm in the code repo.
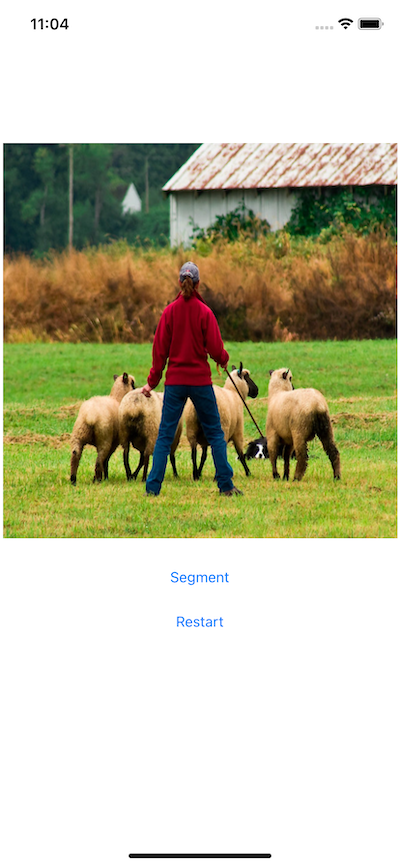
The UI for this app is also similar to that for HelloWorld, except that you do not need the UITextView to show the image classification result. You can also add two buttons Segment and Restart as shown in the code repo to run the model inference and to show back the original image after the segmentation result is shown.
The last step before we can run the app is to connect all the pieces together. Modify the ViewController.swift file to use the predictImage, which is refactored and changed to segmentImage in the repo, and helper functions you built as shown in the example code in the repo in ViewController.swift. Connect the buttons to the actions and you should be good to go.
Now when you run the app on an iOS simulator or an actual iOS device, you will see the following screens:

Recap¶
In this tutorial, we described what it takes to convert a pre-trained PyTorch DeepLabV3 model for iOS and how to make sure the model can run successfully on iOS. Our focus was to help you understand the process of confirming that a model can indeed run on iOS. The complete code repo is available here.
More advanced topics such as quantization and using models via transfer learning or of your own on iOS will be covered soon in future demo apps and tutorials.

{kind=link}